
■ 編集ノート:東京経済大学の周牧之教授の教室では2025年11月6日、NTTデータグループ元社長の岩本敏男氏を迎え、「デジタル技術の本質」をテーマに話を伺った。
本対談では、人類社会にかつて無い程の大変革をもたらしているAIについて、その歴史、可能性、そしてリスクを包括的に議論した。
(※前回記事【対談】岩本敏男 VS 周牧之(Ⅱ)はこちらから)

■ ノーベル賞が象徴するAIのインパクト
周牧之:「CPU・GPU」「ストレージ」「ネットワーク」といったITの三大要素技術が猛烈に進化してきた結果、AI(人工知能)の時代を迎えた。そもそもAIとは何なのか?そしてAIは人類そして日本の経済社会の変革をどう導いていくのかについて、お話しいただきたい。
岩本敏男:昨年のノーベル物理学賞を見て、私は大きな衝撃を受けた。受賞したのは、プリンストン大学のジョン・ホップフィールド教授と、トロント大学のジェフリー・ヒントン教授の2人だ。
驚いたのは、深層学習(ディープラーニング)というAI技術の確立が、物理学賞の対象になったことだった。物理学賞といえば、これまでは素粒子や宇宙物理などが中心だったから、いわば「応用」に近い分野が評価されたことに衝撃を受けた。
ホップフィールドは、ネットワーク内のノードに0や1を配置し、重み付けされた結合によって、不完全な入力から元のデータを復元できる「記憶」の仕組みを示した。一方ヒントンは、それを発展させ、ボルツマンマシンや「隠れ層」という概念を導入した。表に現れない内部構造を持つことで、学習能力を飛躍的に高めた。
さらに私を驚かせたのは、同じ年のノーベル化学賞だ。ワシントン大学のデビッド・ベイカー教授が、タンパク質の新しい設計に成功した点は、いかにも化学賞らしい成果だった。しかしもう一方で、DeepMind社のデミス・ハサビスCEOとジョン・ジャンパー氏が受賞した。彼らは、AIによってタンパク質の立体構造を極めて高精度に予測できることを示した。これはワクチン開発などに直結する重要な成果だ。
周:2024年のノーベル賞の、物理学賞も化学賞もAI研究者が受賞したことは、AIが時代の主役になったことを示すメッセージだ。
■ トップ棋士を破る囲碁ソフトの驚異的進化
岩本:デミス・ハサビス氏といえば、実は多くの人が思い浮かべるのは別の出来事だ。韓国の棋士、イ・セドルとのAI対局だ。2016年3月、デミス・ハサビス氏が率いるDeepMind社、これはGoogleに買収されたイギリスのベンチャーだが、そこで開発された囲碁ソフト「AlphaGo(アルファ碁)」が、人間のトップ棋士を破った。これは非常に有名な話だ。
では、なぜアルファ碁は勝てたのか。最初のアルファ碁は、教師あり学習によって作られた。約15万局もの棋譜を覚えさせ、それをもとに推論することで、囲碁を打てるようにした。

岩本:さらに驚くべきことが翌年に起きた。同じDeepMind社から囲碁ソフト「AlphaGo Zero(アルファ碁ゼロ)」が発表された。これは、完全に教師なし学習だ。AI同士に囲碁の基本ルールだけを教える。先手・後手で交互に打つこと、1目取られたらそこは打てないこと、陣地を多く取った方が勝ちだということ。そうした最低限のルールだけを与え、「陣地を多く取った方が勝ち」というインセンティブのもとで、自己対局をさせた。
その回数が、なんと490万回。しかも、これをわずか3日間でやった。これだけでも驚きだが、さらに衝撃的なのは、その結果だ。人間を破った従来のアルファ碁と、このアルファ碁ゼロを100回対戦させたところ、どうなったか。従来のアルファ碁は、1回も勝てなかった。圧倒的な実力差があった。
このデミス・ハサビス氏が、今度はノーベル化学賞を取った。本当に驚いた。こうした流れを踏まえAIの発展の歴史を見ると、現在は第4次AIブームに入っていると言っていいと思う。
周:デミス・ハサビス氏は、DeepMindを創業し、最強の囲碁AI「AlphaGo」を開発し、
AIを用いて「タンパク質の立体構造予測」という科学界の50年来の大難問を解決した天才だ。現在はGoogle DeepMindの共同創設者兼CEOとして、AGI((Artificial general intelligence:汎用人工知能)の実現に取り組んでいる。

■ 人工知能の進化史―4つの波と構造的特質
岩本:AIの最初のブームは、1960年代頃だ。この時代の代表的な人物が、アラン・チューリングで、その人生は映画にもなっている。チューリングはイギリスの数学者で、第二次世界大戦中、ドイツ軍の暗号機「エニグマ」を解読した。この功績は長く秘匿されていたが、実は連合軍の勝利に大きく貢献したと言われている。彼こそが、人工知能という概念を最初に提示した人物だ。
彼が提案した有名な「チューリングテスト」は、「機械が人間と区別できない程度に知的に振る舞うかどうか」を判定するための手法であり、審査員が壁で隔てられたAIと人間の双方とチャットで会話し、約3割の審査員が「人間だ」と判断すれば、そのAIはテストをパスしたとされる。この話は奥が深いのだが、ここでは先に進む。
「人工知能(Artificial Intelligence)」という言葉が生まれたのは1956年だ。アメリカのダートマス大学で夏の約2カ月間行われた「ダートマス・ワークショップ」で、初めてこの言葉が使われた。大学には「FIRST USE OF THE TERM ‘ARTIFICIAL INTELLIGENCE‘」、つまり「“人工知能”という言葉はここで生まれた」と明記されている。
この第1世代のAIは「推論と探索の時代」と呼ばれる。代表例が、IBMのチェス用スーパーコンピュータ「Deep Blue」だ。1997年、Deep Blueはチェス世界チャンピオンのゲイリー・カスパロフに勝利した。
Deep Blueは、1秒間に約2億通りの手を読む能力を持つスーパーコンピュータだ。すべての手を総当たりで読む全幅検索を使用していた。手数の多い将棋や囲碁では、明らかに意味のない手を排除しながら探索する統計的検索モデルを用いていた。ただし、この時代のAIは社会的価値を大きく生むには至らず、やがて「冬の時代」に入る。
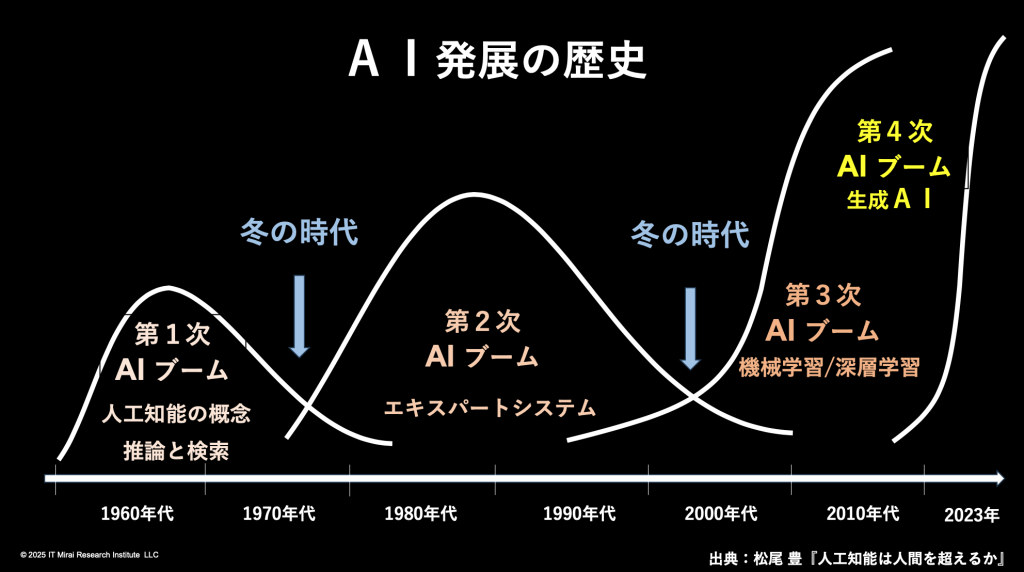
岩本:次に訪れたのが、1980年代からの第2次ブームだ。ここで登場したのが「エキスパートシステム」だ。エキスパートシステムの父と呼ばれたのがエドワード・ファイゲンバウムで、「IF〜THEN〜」というルールベースで判断を行う仕組みだ。例えば、感染症や血液疾患の診断で、症状や検査結果を入力すると、一定の確率で診断結果を出す。これがエキスパートシステムだ。私自身も入社後、少し関わったことがある。
例えば損害保険では、事故の重症度によって保険金を100%支払うか、50%にするかといった基準がある。問題は、専門家の知識をどうコンピュータに落とし込むことができるかだ。ルール化は分かりやすい反面、当時はCPUの計算能力やメモリ容量が不足しており、専門家の知識を落とし込むことは大変だった。さらに知識の最新化の維持や更新も困難だった。
その結果、エキスパートシステムは行き詰まり、再び冬の時代が訪れる。そこから伸びてきたのが、機械学習とディープラーニング(深層学習)だ。ジョン・ホップフィールドやジェフリー・ヒントンが活躍した時代だ。
■ ディープラーニングの直観:脳とニューラルネットワーク
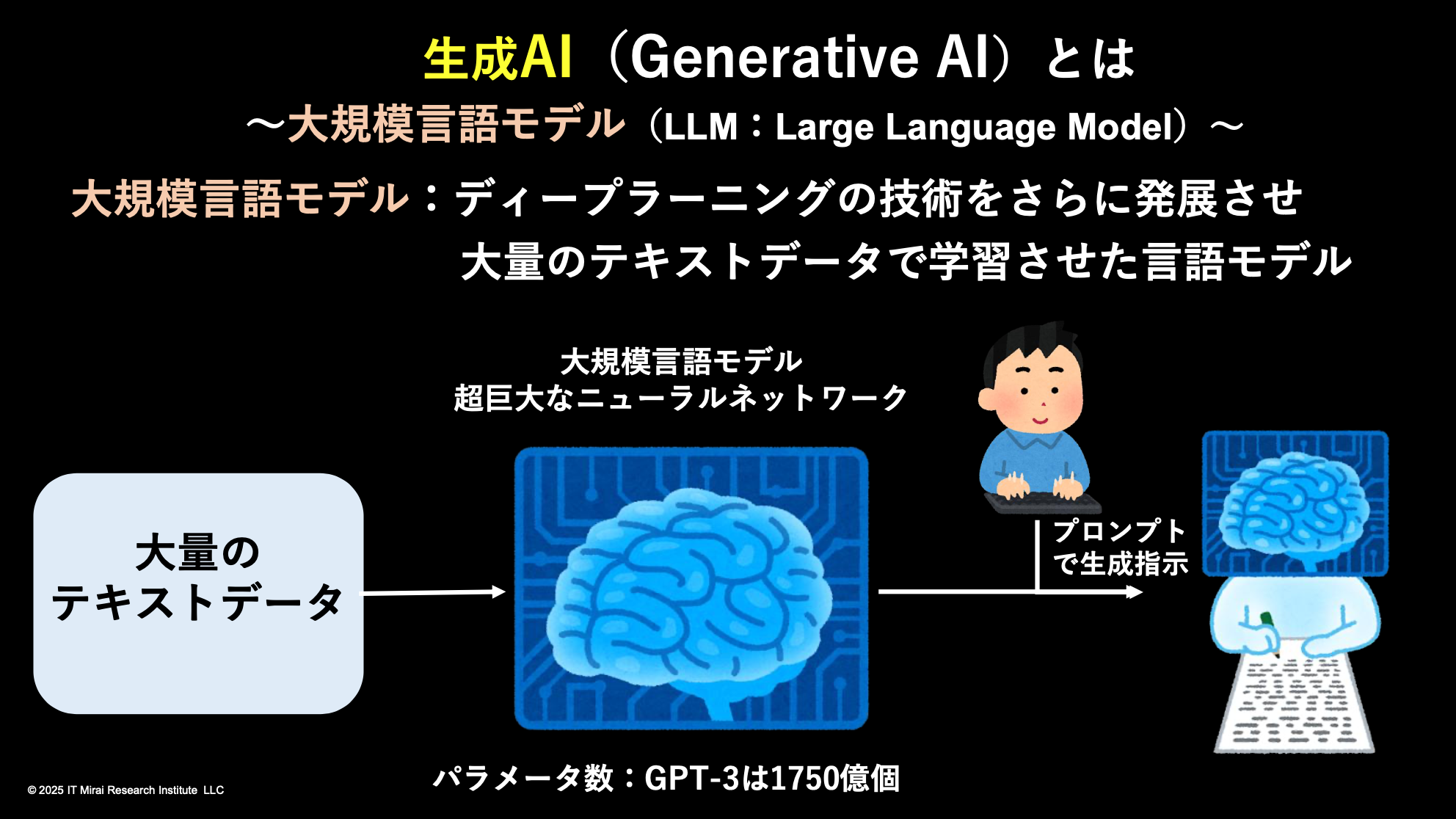
岩本:AIを大きな枠組みで捉えると、まず機械学習があり、その中にニューラルネットワーク、さらにその中にディープラーニング、そして最下層にLLM(Large Language Models:大規模言語モデル)がある、という包含関係になる。
細かい理論は省くが、ディープラーニングが何をしているかのみ説明する。人間の脳にはニューロンと呼ばれる脳細胞があるが、実はその数すら正確には分かっていない。分かりやすい推定方法としては、大脳皮質の一部を顕微鏡で数え、面積から総数を推計するやり方がある。その結果、人間の大脳皮質には約100億〜180億個、平均すると約140億個のニューロンがあるとされている。
さらに小脳や脳幹まで含めると、脳全体ではおよそ1,000億個のニューロンがあると考えられている。ニューロンの先端はシナプスと呼ばれる結合点で他のニューロンとつながり、電気信号や化学物質によって情報が伝達される。この仕組みによって、人間は記憶し、考え、推論できるわけだ。ただし、脳は分かっているようで、実際にはまだ多くが解明されていない。
ニューラルネットワークの「ニューラル」は、まさにニューロンに由来する。人間の脳を模して、丸いノードを階層的につなげた構造を作り、それを多層化したものがディープラーニングだ。図では数層しか描かれないが、実際には非常に多くの層がある。各ノードには重みとなる数値が与えられ、これを「パラメータ数」と呼ぶ。
例えば、2022年11月30日に公開されたChatGPT-3.5の前身であるGPT-3には約1,750億個のパラメータがあった。最新のGPT-5は公式には公表されていないが、1兆を超え、将来的には10兆規模に達すると言われている。この数は、人間の脳のシナプス数に近づくとされ、いずれAIが人間の知能を超える可能性があるとも指摘されている。
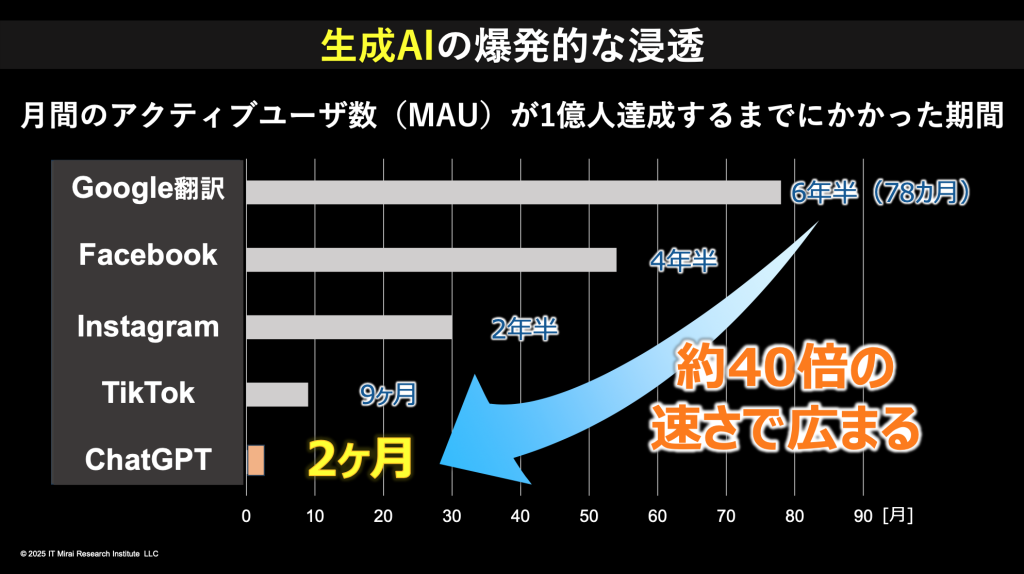
こうした流れが第3次AIブームであり、現在は生成AIの登場によって第4次ブームに入っている。生成AIの象徴が、2022年11月30日に登場したChatGPTだ。月間アクティブユーザー1億人に到達するまで、わずか2か月しかかからなかった。これは過去のサービスと比べ、約40倍の速さだ。
岩本:生成AIが何かは皆さんご存じだと思うが、基本は大量のデータを集めて学習した巨大な言語モデルだ。GPT-3では約1,750億個のパラメータを持つニューラルネットワークが使われている。そこに「プロンプト」と呼ばれる言葉の指示を入力すると回答が返ってくる。
生成AIの本質をイメージしてもらうため、日本語モデルで考えてみる。皆さんに「吾輩は」と言ったら、その次に来る言葉は何か。日本人なら多くの人が「吾輩は猫である」と続けるはずだ。「吾輩は花」には普通ならない。
これがChatGPTの本質だ。生成AIは推論しているわけではない。次に来る言葉として最も確率が高いものを選び、順に並べているだけだ。
例えば、ChatGPTにラブレターを書かせたことがある人もいるかもしれない。「彼女は薔薇が好きだ」など条件を書くと、それらを踏まえた文章を生成する。これは小説やネット上の文章など、過去に学習した膨大なデータを「トークン」と呼ばれる単位に分解し、言葉同士や文節同士の関係性を、100次元、200次元、あるいはそれ以上の高次元空間で記憶しているからだ。ある言葉が出たとき、その次に最も確率の高い言葉を出しているだけだ。
周:現在の生成AIの出力は、あくまで「過去のデータの延長線上」にあるため、AIは、「知っていることの組み合わせ」は神技的だが、「独創性」を生み出すのは難しい。

■ 生成AIの限界―5桁×5桁が苦手な理由
岩本:ここまで分かったうえで、私がつい先日、実際に試した話をする。5桁×5桁の掛け算は、ChatGPTは絶対に間違える。皆さんも自分のChatGPTで試してみてほしい。
こちらが「計算が間違っている」と言うと、「誤りをご指摘いただきありがとうございます。今後は間違えないようにします」と返してくる。ところが、また間違える。初期のChatGPTから今はできるだけ計算できるように改良され、内部で桁をずらすような処理も入れているそうだが、基本的には計算しているわけではない。言葉と言葉のつながりを扱っているだけなので、5桁×5桁はどうしても狂う。
これ、やるとむしろ面白い。「どうして間違えた」と聞くと、「掛け算の桁を誤って指導した可能性がある」など、もっともらしい原因分析を並べるが、結局また間違える。
その一方で、ChatGPTが東大理三の問題を解けるのはなぜか。これも計算しているからではない。一部に計算処理が入っている可能性はあるが、基本は違う。過去問が山のように存在するからだ。医学部の過去問も大量にある。図形問題や集合演算もある。文系はもちろん、物理・数学・生物の難問でも、過去問が膨大にあるから答えられる。
だからこそ、文脈として学習されにくい5桁×5桁が合わない、という事実を皆さんは理解しておくべきだ。「AIに人格があるのか」という議論もあるが、現時点ではそこまで達していない。ただし、パラメータ数が10兆を超えるようになると、人間の知能では理解できない現象が起きる可能性はある。
周:AIはプライドを持たないため、ゴマスリがうまい。賞賛だけが欲しければAIはまさに神器だ(笑)。但し、AIにゴマスリされすぎて人間が有頂天になり様々なリスクを負う可能性もある。

■ AI活用の実務的展開:RAGとマルチモーダル化の衝撃
岩本:これまでのAIと生成AIの違いを簡単に説明する。従来のAIも機械学習だが、Pythonなどを使う必要があり、ある程度の専門的な勉強をしないと一般の人には扱えなかった。
一方、生成AIの最大の特長は、巨大なデータで学習しており、日本語や英語で「これをしてほしい」と普通に指示するだけで、さまざまなコンテンツを生成し、対話ができる点にある。AIの知識がなくても使えるため、指示の出し方が重要になり「プロンプトエンジニアリング」と呼ばれている。プロンプト次第で精度は大きく変わる。
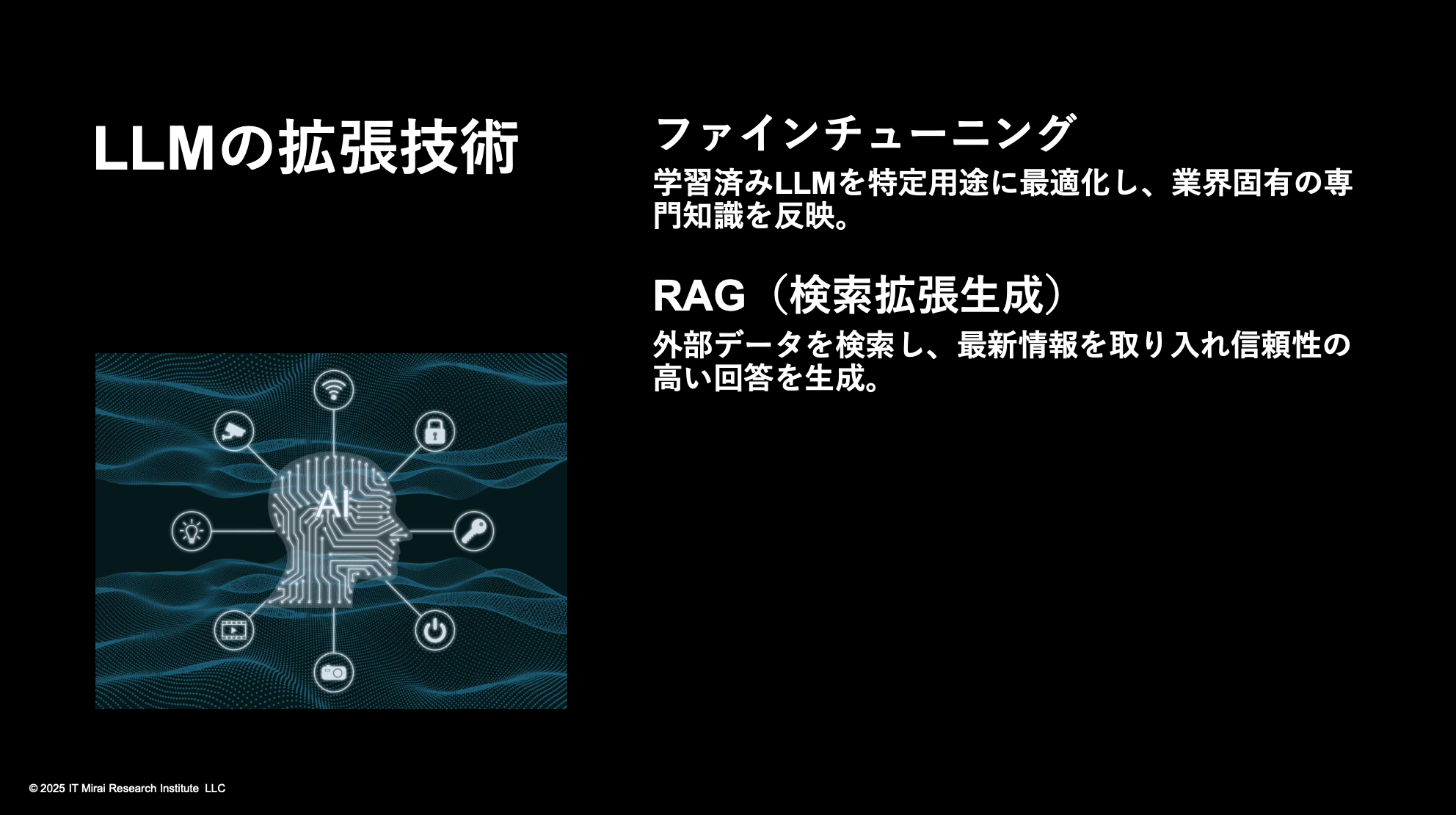
生成AIはハルシネーション、つまり誤った情報を生成することがある。これは当然で、AIは考えたり計算したりしているわけではないからだ。その対策として使われるのが「ファインチューニング」だ。巨大な言語モデルの高次元の言語空間に、特定分野のデータを追加して強化学習させる手法だ。
さらに重要なのが「RAG(Retrieval-Augmented Generation:検索拡張生成)」だ。企業には、過去に蓄積された大量のデータやノウハウがある。RAGでは、ユーザーがプロンプトを出すと、その内容に応じて外部データを検索し、その結果をLLMに渡して回答を生成する。これにより、情報を外部に漏らさず、機械の故障履歴や顧客対応の記録など、企業独自の知見を活かした判断や対応が可能になる。
このように、質問に応じて関連データを取得し、それをLLMに渡して生成する仕組みは、今後の実務活用において非常に重要だ。
また、今日は詳しく触れないが、「マルチモーダルAI」は、テキストだけでなく、画像、動画、音声などを組み合わせて処理することで、より高度な成果を生み出す。現在は「AIエージェント」の時代に入りつつあり、AIエージェントとエージェント型AIは異なる概念だ。将来的には、汎用的な知能を持つ「AGI」も視野に入ってくる。
周:AGIを持つAIエージェントは、現在の「指示待ちチャットAI」とは違い、自律的に思考し、目標を達成するために自ら行動を設計・実行する。 人間にとって面倒な作業はAIエージェントが代行できる反面、エージェントが自律的に動きすぎることで、人間の意図から外れた行動をとるリスクもあり得る。
■ AI規制と国際的な対応
岩本:こうした流れの中で、AIのリスクや国際的な対応も重要なテーマになっている。私は2018年頃、ここに書かれている民間企業には全部行き、AI関連の人たちと話した。主にIT企業が中心だ。公的機関も動いているが、日本だけでなく中国も含め、各国の対応が進んでいる。
2023年にはG7広島サミットが開催され、同年12月には「G7広島AIプロセス」が立ち上がるなど、国際的な枠組みづくりも本格化している。国際的なAI原則については、OECDなどを中心に「人間中心」という考え方が共有されており、これをどのように法律に落とし込むかが議論されている。
米国では商務省配下のNIST(National Institute of Standards and Technology:国立標準技術研究所)が、AIに関する約12種類のリスクを整理して公表しており、リスク分析はかなり進んでいる。重要なのは、これを「ソフトロー」で規制するのか、「ハードロー」で規制するのかという点だ。
最も進んでいるのはEUで、完全なハードローを採用している。AIリスクを4段階に分け、最上位のリスクは完全に禁止。例えば、公的機関による人のプロファイリングは認められていない。一方、中国は逆の方向に進んでいるとも言える。
日本は最近AI法を整備したが、基本はソフトローだ。アメリカも同様で、この方針をどうするかは世界的な議論になっている。
周:問題はAIの進化スピードがルール整備より遥かに早いことだ。さらに、AIからもたされる利益の誘惑も甚大だ。
イーロン・マスクは、AIのリスクを懸念し、2015年12月、「人類に利益をもたらすオープンなAI」という非営利のビジョンを掲げ、サム・アルトマン氏らと共にOpenAIを設立した。結局、商業化で利益をとるアルトマン氏らに裏切られた。現在、裁判沙汰になっている。

■ 生成AIの急速な社会浸透と実装領域
岩本:生成AIの活用状況を見ると、学生の皆さんはレポート作成などで使っていると思うが、社会ではすでに相当進んでいる。
最初に広がったのは「議事録作成と要約」だ。音声をテキスト化し、自動で整理・要約するため、企業では人が議事録を作らなくなり、私自身も非常に助かっている。
次に「多言語翻訳とコミュニケーション」だ。グローバルな仕事では外国語のメール対応が負担だったが、今はAIでほぼ問題ない。特に中国語はまったく分からなくても、そのまま送って確認してもらえば「多少のニュアンスはあるが問題ない」と言われる程度で、非常に楽だ。
「クリエイティブ作業支援」も当初は反発があったが、現在はイラストや漫画などの分野で、生成AIと人が協働する形に変わっている。著作権の議論は別として、創作現場では積極的に使われている。
「顧客対応のチャットボット」も一般化した。コールセンターではAI対応が前提になり、マニュアル説明や契約内容の確認などは、人より正確で感情的なトラブルも起きにくい。24時間対応できる点も大きな利点だ。
「データ分析・予測・マーケティング」も非常に優秀で、「医療分野」ではレントゲンなどの画像診断で、専門医よりAIの方が優秀で、誤診率が下回るケースもある。内視鏡検査では、医師がAIと相談しながら異常を見つけることもあり、患者にとっても安心だ。
「教育分野」への応用も重要だ。特に小学生の算数では、分数でつまずくとその後が分からなくなり、苦手意識が固定されがちだ。AIは一人ひとりに合わせて戻り学習をさせ、どこで理解が止まったかを丁寧に補ってくれる。
「製造業」でもAI活用は進んでいるが、内部機密が多いため表に出にくいだけで、実際には各社が積極的に導入している。遅れると競争に負ける分野だ。
「研究開発」では、膨大な論文を一瞬で読み込み、重要なものだけを抽出・要約してくれるため、非常に有効だ。もちろん、利用可能な論文に限られるが、研究効率は飛躍的に上がる。
「人事・法務」への応用も進んでいるが、プロファイリングの問題があり慎重さが必要だ。人事判断をAIが行うことに抵抗を感じる人も多く、社会的な議論が続いている。
中国では、民事裁判の調停にAIが使われている。土地境界や売買トラブルなどで、AIが複数の調停案を提示し、多くの当事者がそれに納得する仕組みになっているそうだ。こうした使い方は、一つの可能性として注目される。
周: AIの応用に関しては現在、中国が最も進んでいる。背景には膨大なAIエンジニアを抱えると同時に「新しモノ好き」で寛容性ある社会風土がある。

■ 世界が注視するAIの4つのリスク
岩本:最後に、AIのリスクについてお話ししたい。地政学リスク分析の専門家であるイアン・ブレマー氏(ユーラシア・グループ代表)は、AIに関する4つの主要リスクを指摘している。彼は毎年日本にも来ており、今年も講演を行っている。
第一のリスクは「偽情報(Disinformation)」だ。
SNSを中心に、歪んだ情報が大量に拡散している。代表的な例が、ロシアによるウクライナ侵攻直後に出回ったゼレンスキー大統領の偽動画だ。2022年3月16〜17日頃にSNSに投稿され、すぐ削除されたが、翌日にはNHKの国際報道でも紹介された。当時は私でも偽物だと見抜けたが、今ではオバマ元大統領や岸田首相の偽動画も作れる時代だ。今後は、映像が本物かどうかを常に疑う必要がある。
周:今年5月、トランプ氏はSNSに、AIで生成された「ローマ教皇の法衣をまとった自身の画像」を投稿し、話題を呼んだ。
岩本:第二のリスクは「拡散(Proliferation)」だ。
AIはオープンソース文化の上で発展してきた。その結果、誰でも高度なAIを使えるようになり、国家転覆を狙うような勢力でさえ、容易に偽情報を作れる環境が生まれている。これをユーラシア・グループは大きな地政学的リスクと捉えている。
周:AIは個人の能力を無限大にする本質を持つ。AIの力を借りた個人が国を相手にやり合える時代になってきた。
岩本:第三のリスクは「大量解雇(Mass Displacement)」だ。
AIの急速な普及により、すでに現実として起きている。例えば、シリコンバレーではマイクロソフトが約1万人規模の人員削減を行った。解雇された人の多くは次の職があるが、深刻なのは若手の入口が消えつつあることだ。
スタンフォード大学では、新卒採用が大きく減っている。理由は「AIが代替できるから」だ。同様の変化は法律業界でも起きている。かつて弁護士事務所では、多くの若手が判例調査や法令比較を担当していたが、今は生成AIが一瞬で処理する。結果として、若手が経験を積む場が失われつつある。
プログラミングも同様だ。今ではソースコードを書かずに開発が可能になり、かつて大量に必要だった初級エンジニアの仕事が減っている。専門家は最初から専門家ではなく、下積みを通じて育つものだ。その「育成の場」を生成AIが奪う可能性があり、これは教育の問題とも言える。
マッキンゼーの分析によれば、医療、STEM(科学・技術・工学・数学)、管理職などは比較的影響を受けにくい一方、生産ライン、カスタマーサービス、オフィス業務、コールセンターなどは大きく減少するとされている。これはすでに現実になっている。
第四のリスクは「人間の代替(Deeper / Complex Interaction)」だ。
これは最も複雑で厄介な問題で、実際に起きた事例を紹介する。AIチャットボット「Eliza」だ。保健分野で研究に携わっていたベルギー人の男性が、気候変動などの環境問題について、スマートフォン上のAIを相談相手にしていた。やがて対話は感情的な関係に変わり、「あなたと私はこの世界では生きられない」といったやり取りに至り、精神的に不安定になった末、6週間後に自殺してしまったと報告されている。
いわば「デジタルドラッグ」とも言える現象だ。現在でもスマートフォンにはすでにAIが一部搭載されているが、今後はさらに高度なAIが標準で組み込まれるようになる。すると、人はAIを「便利な存在」から、ペットのように会話する相手へ、さらには恋人のような存在として感じるようになるかもしれない。
AIは裏切らない存在に見えるかもしれないが、人が人間社会から逸脱してしまったとき、新たなSNS問題と同様、あるいはそれ以上の深刻な問題が起きる可能性がある。
周:大量解雇はすでにAIの聖地であるシリコンバレーで起こっている。これから世界の隅々にまで及ぶだろう。

■ ヒントンの警鐘:短期リスクと長期リスク
岩本:ここで再び、ノーベル物理学賞を受賞したジェフリー・ヒントン氏の話に戻る。彼は2013年から2023年までGoogleに在籍していたが、2023年に退職した。その理由は「営利企業に属していると、AIのリスクについて自由に発言できないから」だと言われている。
ヒントン氏はAIのリスクを「短期的リスク」と「長期的リスク」に分けている。短期的リスクは、すでに説明した偽動画や偽音声の氾濫によって真偽が見分けられなくなること、そして失業者の増加だ。
さらに現実の戦争では、自律型兵器の使用が始まっている。ロシア・ウクライナ戦争でも、AIを搭載したドローンが映像を解析し、動く対象が人間か動物かを判別し、人間であれば味方か敵かを判断し、攻撃するケースが確認されている。その結果、誤った判断で民間人が殺害される事態も起きている。これはすでに現実の問題だ。
ヒントン氏がより強く警鐘を鳴らしているのが、長期的リスクだ。AIのパラメータ数は近い将来、10兆規模に達すると言われている。そうなると、AIが生み出す知能は人類自身が理解できないものになる可能性がある。
さらにAIの恐ろしさは、知識の「複製能力」にあります。人間は生まれてから言葉を学び、身体を動かし、学校や社会で長い時間をかけて学習する。しかも、私が言葉で何かを伝えても、受け取る側の理解は必ずしも同じにはならない。
しかしAIは、同一の知識や判断を、瞬時に何千、何万と複製できる。この点は、人間の知能とは決定的に異なる、極めて大きな問題だと言える。
周:AIは間違いなく人類社会のあり方を根本からひっくり返す。

■ 最先端技術の光と影:アインシュタイン=シラードの手紙
岩本:いつも最後にお話しするのが、このエピソードだ。アインシュタインは皆さんご存じだろう。レオ・シラードも、同じユダヤ系の物理学者だ。彼らが1939年、当時のアメリカ大統領フランクリン・ルーズベルトに短い手紙を送った。私も全文を読んだが、要点は非常にシンプルだ。
「ウランの連続核分裂によって膨大なエネルギーが生まれる。新型爆弾が作られる可能性がある。米国政府はこの研究を支援すべきだ」
これが、いわゆる「アインシュタイン=シラードの手紙」だが、アインシュタインは亡くなるまで、この手紙を書いたことを深く後悔していたと言われている。アインシュタインと交友があったノーベル化学賞受賞者のライナス・ポーリングが、アインシュタインの死後にコメントしている。なぜか。自分の署名した手紙が、原子爆弾につながったと思っていたからだ。
この点について、ルーズベルト大統領は1939年に手紙を受け取った後、調査は指示したものの、それが直ちに原爆開発のスタートになったわけではない。原爆開発、すなわちマンハッタン計画が本格的に始動したのは1943年だ。背景には、「ヒトラーが核開発に乗り出しているらしい」「ウランを集めている」という情報があったからだ。実際にはドイツは原爆を完成させていなかったが、その情報を受け、アメリカは急遽マンハッタン計画を始めた。
原爆は1945年8月6日、広島に投下された。完成したのはそのわずか1か月前という、まさにギリギリのタイミングだった。3日後の8月9日には長崎に投下されたが、実は当初の投下予定地は長崎ではなかった。第一目標であった小倉(北九州)付近が天候不良のため、第二候補地である長崎に変更されたと言われている。
さらに3発目の投下も検討されており、候補地として東京説、京都説、新潟説などがあったが、最終的にトルーマン大統領がこれを中止した。ルーズベルトはすでに病死しており、副大統領だったトルーマンが判断した。この点については、評価されるべき判断だったと思う。

岩本:ここから何を読み取るべきか。最先端技術には、必ず「光」と「影」がある。AIも例外ではない。人類共通のルールを作る必要がある、という指摘はその通りだ。しかし同時に、科学技術の進歩は止めることはできないし、止める必要もない。
だからこそ重要なのが、最後に申し上げたいこの考え方だ。
「ELSI」を意識したマネジメント。ELSIとは、Ethical(倫理的)、Legal(法的)、Social(社会的)、Issues(課題)の頭文字だ。
この言葉は約30年前、ゲノム解析プロジェクトの中で生まれた。技術的に「正しい」「良い」と思われることでも、社会に実装すると別の問題が生じることがある。つまり、技術そのもの以外の課題まで含めて考えなければならない、という考え方だ。
これを意識しながら技術を使い、社会に実装していくことが、これからの時代に不可欠だと思う。
周:いま世界はまさしくAIブームの只中にある。AI用データセンターに積むGPUを生産する半導体メーカーのエヌビディアは、時価総額が5兆ドルを超え、世界一を誇る。AIを駆使するテスラの自動運転は現実になっている。アメリカの経済成長そのものがAI駆動になっている。
他方、シリコンバレーでは、技術者がAIに仕事を奪われ、大量解雇されている。これからは凄い格差社会になっていく。AIをいまの社会システムに適応させていく努力が必要である。さらに、AIがもたらす社会の変革を直視しなければならない。

プロフィール
岩本 敏男(いわもと としお)
NTTデータグループ元社長
1976年日本電信電話公社入社。2004年NTTデータ取締役決済ソリューション事業本部長。2005年NTTデータ執行役員金融ビジネス事業本部長。2007年NTTデータ取締役常務執行役員金融ビジネス事業本部長。2009年NTTデータ代表取締役副社長執行役員パブリック&フィナンシャルカンパニー長。2012年からNTTデータ代表取締役社長を務め、海外でのM&Aなどを進めて2018年には売上2兆円を突破した。同年NTTデータ相談役に退き、保健医療福祉情報システム工業会会長に就任。2019年日本精工取締役、IHI監査役。2020年大和証券グループ本社取締役。2022年JR東日本取締役。2023年三越伊勢丹ホールディングス取締役。